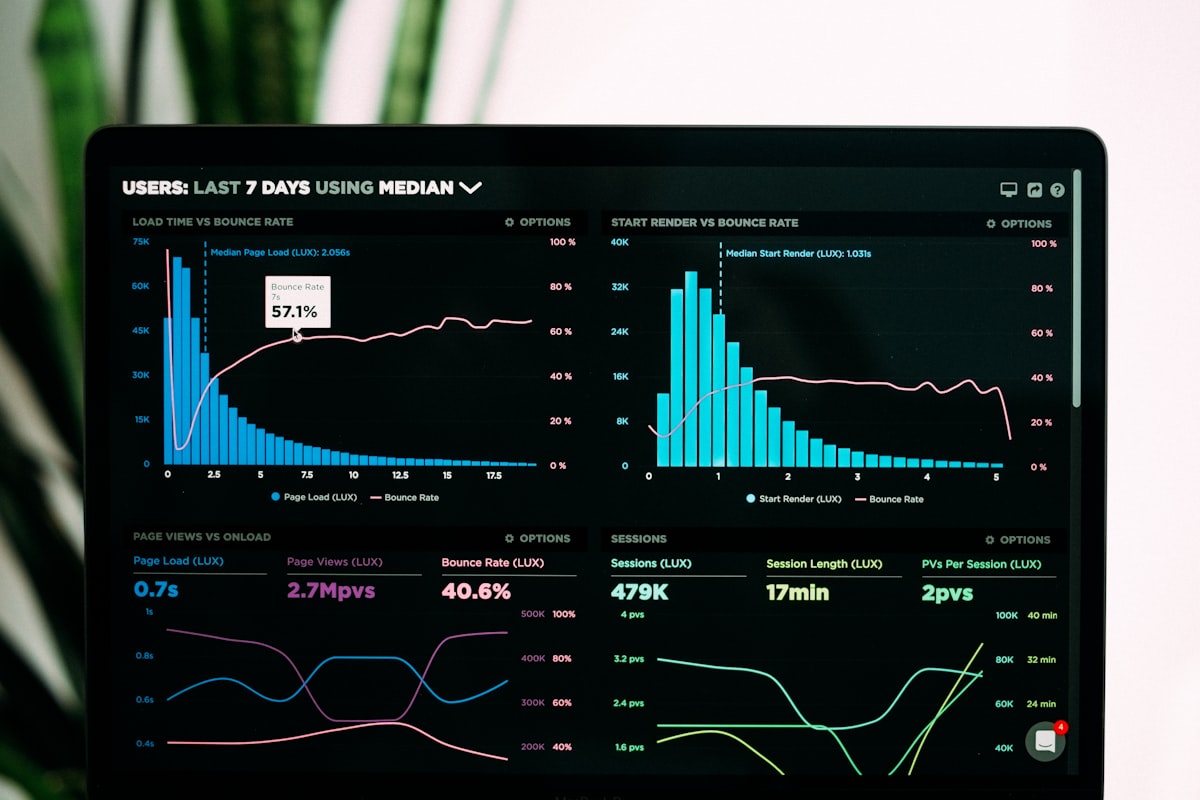
Vous avez déployé LibreChat en interne pour donner à vos équipes un accès unifié aux LLMs. Excellent choix. Mais savez-vous combien de tokens vos collaborateurs consomment chaque jour ? Quels modèles sont les plus utilisés ? Quels départements génèrent le plus de coûts IA ? Sans monitoring, vous pilotez à l’aveugle.
Dans cet article, nous vous montrons comment déployer un tableau de bord Grafana complet pour mesurer l’usage IA en entreprise via LibreChat – avec toutes les métriques qui comptent pour piloter votre stratégie IA.
Pourquoi monitorer votre usage IA ?
L’observabilité de vos outils IA n’est pas un luxe technique. C’est une nécessité opérationnelle et financière pour plusieurs raisons :
- Maîtrise des coûts : les tokens coûtent de l’argent. Sans monitoring, les surprises sur la facture API arrivent vite.
- Optimisation des modèles : peut-être que 80% des usages pourraient être couverts par un modèle 10x moins cher.
- Adoption et ROI : mesurer qui utilise vraiment l’outil et comment justifie l’investissement auprès du management.
- Sécurité et conformité : détecter les usages anormaux ou non conformes à vos politiques.
Architecture de la stack de monitoring
Notre stack repose sur trois composants open source :
- LibreChat : la plateforme de chat IA unifiée, qui expose des métriques via son API interne
- Prometheus : collecteur et base de données de séries temporelles pour les métriques
- Grafana : visualisation des métriques avec dashboards configurables
L’architecture est simple : LibreChat expose ses métriques dans un format compatible Prometheus, Prometheus les scrape à intervalles réguliers, et Grafana interroge Prometheus pour afficher les dashboards.
Configuration de LibreChat pour l’observabilité
Activation des métriques Prometheus
Dans votre fichier librechat.yaml, ajoutez la configuration suivante pour activer l’export de métriques :
monitoring:
enabled: true
prometheus:
enabled: true
port: 9090
path: /metrics
LibreChat exposera alors des métriques sur le port 9090 au format Prometheus.
Métriques disponibles par défaut
LibreChat expose nativement les métriques suivantes :
librechat_tokens_total: total des tokens consommés (prompt + completion)librechat_tokens_by_model: tokens par modèle LLM utilisélibrechat_tokens_by_user: tokens par utilisateurlibrechat_conversations_total: nombre total de conversationslibrechat_active_users: utilisateurs actifs (daily/weekly/monthly)librechat_api_latency: latence des appels API aux différents LLMslibrechat_errors_total: erreurs par type et par modèle
Configuration de Prometheus
Ajoutez la cible LibreChat dans votre prometheus.yml :
scrape_configs:
- job_name: 'librechat'
static_configs:
- targets: ['librechat:9090']
scrape_interval: 30s
metrics_path: /metricsAvec Docker Compose, voici la configuration complète de votre stack :
version: '3.8'
services:
librechat:
image: ghcr.io/danny-avila/librechat:latest
ports:
- "3080:3080"
- "9090:9090"
prometheus:
image: prom/prometheus:latest
ports:
- "9091:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=votremotdepasseCréation du dashboard Grafana
Connexion à Prometheus comme datasource
Dans Grafana (http://localhost:3000), allez dans Configuration → Data Sources → Add data source, sélectionnez Prometheus et entrez l’URL : http://prometheus:9090.
Les 6 panels essentiels
Panel 1 : Tokens consommés par jour
sum(increase(librechat_tokens_total[24h]))Ce panel vous donne une vue quotidienne de la consommation totale. Ajoutez une alerte Grafana si le total dépasse votre seuil budgétaire journalier.
Panel 2 : Coût estimé par modèle
sum by (model) (increase(librechat_tokens_total[24h])) * on(model) group_left() librechat_token_cost_per_1kCe panel nécessite de configurer les coûts par modèle dans LibreChat. Il vous montre en temps réel le coût engendré par chaque modèle.
Panel 3 : Top 10 utilisateurs par consommation
topk(10, sum by (user) (increase(librechat_tokens_by_user[7d])))Identifiez vos «super utilisateurs» et comprenez leurs patterns d’usage pour former les autres équipes.
Panel 4 : Utilisateurs actifs (DAU/WAU/MAU)
librechat_active_users{period="daily"}Le taux d’adoption est votre principal KPI pour mesurer le ROI de votre déploiement LibreChat.
Panel 5 : Distribution des modèles utilisés
sum by (model) (increase(librechat_tokens_by_model[7d]))Un pie chart qui révèle si vos équipes utilisent des modèles trop chers pour des tâches simples. Très utile pour guider les recommandations de modèle par cas d’usage.
Panel 6 : Latence P95 par modèle
histogram_quantile(0.95, sum by (le, model) (rate(librechat_api_latency_bucket[5m])))Détectez les modèles qui ralentissent l’expérience utilisateur et anticipez les problèmes de performance.
Métriques avancées : coûts par département
Si vous avez configuré LibreChat avec des groupes d’utilisateurs par département, vous pouvez créer des métriques de coût par équipe :
sum by (department) (increase(librechat_tokens_by_user[30d])) * on(user) group_left(department) librechat_user_infoCette vue permet aux managers de voir la consommation IA de leur équipe et de justifier ou ajuster les budgets alloués.
Alertes à configurer
Voici les 4 alertes Grafana que nous recommandons à chaque déploiement LibreChat :
- Dépassement budgétaire : coût journalier > seuil défini (ex: 50€/jour)
- Pic d’utilisation anormal : consommation horaire > 3x la moyenne sur 7 jours
- Taux d’erreur élevé : erreurs API > 5% des requêtes sur 15 minutes
- Latence dégradée : P95 > 30 secondes sur un modèle
Intégration avec Slack pour les alertes
Configurez un webhook Slack dans Grafana pour recevoir les alertes directement dans votre channel #ia-ops :
alerting:
contact_points:
- name: Slack IA Ops
slack:
url: https://hooks.slack.com/services/VOTRE_WEBHOOK
channel: "#ia-ops"
message: "Alerte LibreChat : {{ .GroupLabels.alertname }} - {{ .CommonAnnotations.summary }}"Conclusion
Monitorer votre usage LibreChat avec Grafana est un investissement de quelques heures qui vous fait économiser des mois d’approximations budgétaires. En quelques dashboards bien configurés, vous passez d’un déploiement IA «à l’aveugle» à un pilotage data-driven avec des KPIs clairs : adoption, coûts, performance et ROI.
Besoin d’aide pour déployer LibreChat avec monitoring Grafana dans votre infrastructure ? L’équipe Digitalizor vous accompagne de l’installation à la configuration des dashboards métier.
🏗️ Architecture : LibreChat → Prometheus → Grafana
Pipeline complet de monitoring IA en entreprise
LibreChat
Utilisateurs
/metrics
Prometheus
stockage TSDB
datasource
Grafana
& Alertes
PagerDuty/Slack
Alertes
PagerDuty
CPU / RAM / Disk
:9100
Routage alertes
:9093
recommandé
📋 Les 10 métriques clés à monitorer sur votre stack IA
| # | Métrique | Description | Panel Grafana | Seuil d’alerte |
|---|---|---|---|---|
| 1 | librechat_requests_total | Nombre total de requêtes IA envoyées | Time series / Counter | > 10K/h |
| 2 | librechat_tokens_used_total | Tokens consommés (input + output) | Gauge / Stat panel | > 80% budget |
| 3 | librechat_active_users | Utilisateurs actifs en temps réel | Stat / Big number | > 500 simultanés |
| 4 | librechat_response_latency_p95 | Latence au 95e percentile (ms) | Heatmap / Histogram | > 8 000ms |
| 5 | librechat_errors_rate | Taux d’erreurs API (timeouts, 4xx, 5xx) | Time series / Alert | > 2% |
| 6 | librechat_cost_usd_total | Coût cumulé en $ (calculé via tokens) | Stat / Budget tracker | > 90% budget |
| 7 | librechat_model_usage_ratio | Répartition des modèles utilisés (%) | Pie chart | Informatif |
| 8 | librechat_conversations_per_user | Conversations moyennes par utilisateur/jour | Bar chart | Informatif |
| 9 | process_cpu_usage | CPU utilisé par LibreChat (Node.js) | Gauge / Time series | > 80% |
| 10 | nodejs_heap_used_bytes | Mémoire heap Node.js consommée | Gauge / Alert | > 1.5GB |
⚙️ Configuration Prometheus : prometheus.yml pour scraper LibreChat
# prometheus.yml - Configuration pour monitorer LibreChat
global:
scrape_interval: 15s # Collecte toutes les 15 secondes
evaluation_interval: 15s # Evaluation des regles toutes les 15s
external_labels:
monitor: 'librechat-prod'
environment: 'production'
# Regles d'alerte
rule_files:
- "alerts/librechat_alerts.yml"
# Alertmanager
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
# Scrape configs
scrape_configs:
# LibreChat application metrics
- job_name: 'librechat'
static_configs:
- targets: ['librechat:3080']
metrics_path: '/metrics'
scrape_interval: 30s
scrape_timeout: 10s
relabel_configs:
- source_labels: [__address__]
target_label: instance
replacement: 'librechat-prod'
# Node Exporter - metriques systeme (CPU, RAM, Disk)
- job_name: 'node'
static_configs:
- targets: ['node-exporter:9100']
relabel_configs:
- source_labels: [__address__]
target_label: instance
# MongoDB metrics (si utilise par LibreChat)
- job_name: 'mongodb'
static_configs:
- targets: ['mongodb-exporter:9216']
# Prometheus lui-meme
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# Exemple de fichier alerts/librechat_alerts.yml :
# groups:
# - name: librechat
# rules:
# - alert: HighErrorRate
# expr: rate(librechat_errors_total[5m]) > 0.02
# for: 2m
# labels:
# severity: critical
# annotations:
# summary: "Taux d'erreur LibreChat eleve"
📊 Dashboard Grafana : JSON importable pour LibreChat
{
"title": "LibreChat - Monitoring IA",
"uid": "librechat-monitoring-v1",
"tags": ["librechat", "ia", "monitoring"],
"timezone": "Europe/Paris",
"schemaVersion": 38,
"refresh": "30s",
"time": { "from": "now-24h", "to": "now" },
"panels": [
{
"id": 1,
"title": "Requetes totales (24h)",
"type": "stat",
"gridPos": { "x": 0, "y": 0, "w": 4, "h": 4 },
"targets": [{
"expr": "increase(librechat_requests_total[24h])",
"legendFormat": "Requetes"
}],
"options": { "colorMode": "background", "graphMode": "area" },
"fieldConfig": { "defaults": { "color": { "mode": "thresholds" },
"thresholds": { "steps": [
{"color": "green", "value": null},
{"color": "orange", "value": 5000},
{"color": "red", "value": 10000}
]}
}}
},
{
"id": 2,
"title": "Tokens consommes (24h)",
"type": "stat",
"gridPos": { "x": 4, "y": 0, "w": 4, "h": 4 },
"targets": [{
"expr": "increase(librechat_tokens_used_total[24h])",
"legendFormat": "Tokens"
}]
},
{
"id": 3,
"title": "Cout estimé ($)",
"type": "stat",
"gridPos": { "x": 8, "y": 0, "w": 4, "h": 4 },
"targets": [{
"expr": "increase(librechat_cost_usd_total[24h])",
"legendFormat": "USD"
}],
"fieldConfig": { "defaults": { "unit": "currencyUSD" } }
},
{
"id": 4,
"title": "Latence p95 (ms)",
"type": "timeseries",
"gridPos": { "x": 0, "y": 4, "w": 12, "h": 6 },
"targets": [{
"expr": "histogram_quantile(0.95, rate(librechat_response_latency_bucket[5m])) * 1000",
"legendFormat": "p95 latency"
}],
"fieldConfig": { "defaults": { "unit": "ms",
"thresholds": { "steps": [
{"color": "green", "value": null},
{"color": "orange", "value": 5000},
{"color": "red", "value": 8000}
]}
}}
}
]
}
🐍 Script Python : Export des métriques mensuelles vers CSV
"""
Export mensuel des metriques LibreChat depuis Prometheus vers CSV
Usage: python export_metrics.py --month 2026-05
"""
import requests
import pandas as pd
from datetime import datetime, timedelta
import argparse
import os
PROMETHEUS_URL = os.getenv("PROMETHEUS_URL", "http://localhost:9090")
def query_prometheus(query: str, start: datetime, end: datetime, step: str = "1h") -> list:
"""Interroge Prometheus avec une requete PromQL sur une plage temporelle."""
url = f"{PROMETHEUS_URL}/api/v1/query_range"
params = {
"query": query,
"start": start.isoformat() + "Z",
"end": end.isoformat() + "Z",
"step": step
}
resp = requests.get(url, params=params, timeout=30)
resp.raise_for_status()
return resp.json()["data"]["result"]
def export_monthly_metrics(year: int, month: int) -> pd.DataFrame:
"""Exporte les metriques cles pour un mois donne."""
start = datetime(year, month, 1)
if month == 12:
end = datetime(year + 1, 1, 1) - timedelta(seconds=1)
else:
end = datetime(year, month + 1, 1) - timedelta(seconds=1)
print(f"Export metriques : {start.strftime('%Y-%m')} ...")
metrics_queries = {
"requests_total": "increase(librechat_requests_total[1h])",
"tokens_used": "increase(librechat_tokens_used_total[1h])",
"cost_usd": "increase(librechat_cost_usd_total[1h])",
"active_users": "librechat_active_users",
"latency_p95_ms": "histogram_quantile(0.95, librechat_response_latency_bucket) * 1000",
"error_rate_pct": "rate(librechat_errors_total[1h]) * 100",
}
dfs = []
for metric_name, query in metrics_queries.items():
results = query_prometheus(query, start, end)
for series in results:
for timestamp, value in series["values"]:
dfs.append({
"timestamp": datetime.utcfromtimestamp(float(timestamp)),
"metric": metric_name,
"value": float(value) if value != "NaN" else None,
"labels": str(series.get("metric", {}))
})
df = pd.DataFrame(dfs)
if df.empty:
print("Aucune donnee trouvee.")
return df
# Pivot pour avoir une colonne par metrique
df_pivot = df.pivot_table(index="timestamp", columns="metric", values="value", aggfunc="sum")
df_pivot.reset_index(inplace=True)
# Totaux mensuels
print("\nTotaux mensuels :")
for col in ["requests_total", "tokens_used", "cost_usd"]:
if col in df_pivot.columns:
print(f" {col}: {df_pivot[col].sum():,.0f}")
return df_pivot
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--month", default=datetime.now().strftime("%Y-%m"), help="Format: YYYY-MM")
args = parser.parse_args()
year, month = map(int, args.month.split("-"))
df = export_monthly_metrics(year, month)
if not df.empty:
filename = f"librechat_metrics_{args.month}.csv"
df.to_csv(filename, index=False)
print(f"\nExporte dans : {filename}")